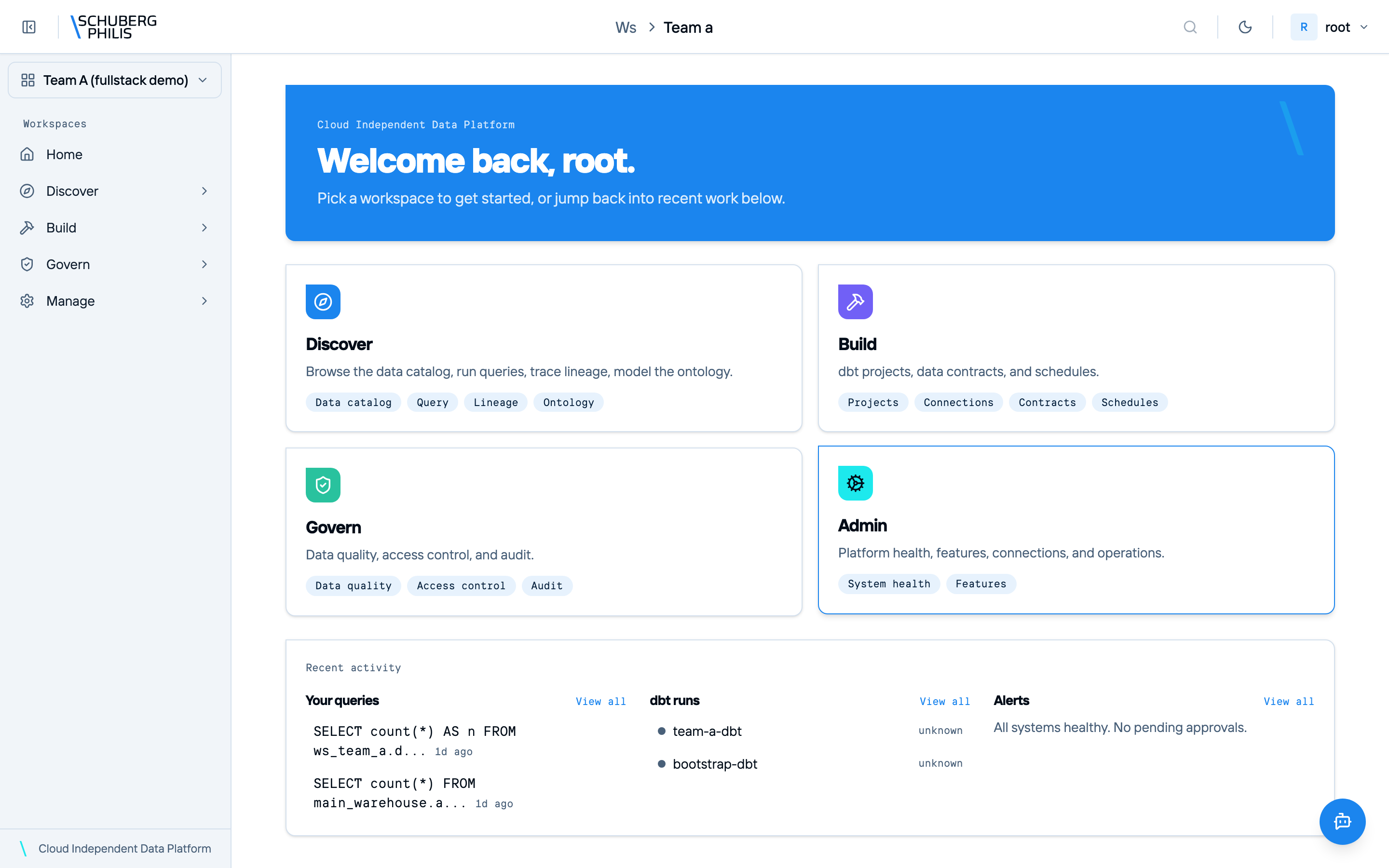
Data Explorer
Browse catalogs, namespaces, and tables with schema inspection and Databricks-style column profiling.
A sovereign, open-source data platform built on Apache Iceberg, Polaris, SQE, and OPA. Enterprise-grade security, AI-assisted analytics, and total cloud independence — zero proprietary lock-in. Runs on Kubernetes: hyperscaler, sovereign cloud, private cloud, or on-prem.
Open standards end to end: Apache Iceberg · Polaris · OPA · Keycloak · S3. No vendor IAM, no proprietary format.
Cloud-native warehouses create deep dependency on a single provider. Migrating away costs millions and takes years.
GDPR, DORA, and NIS2 demand control over where data lives and who can access it. Proprietary platforms make compliance a moving target.
Catalogs, query engines, access control, and storage — each with its own API, auth model, and upgrade cycle. Rising cost, audit nightmares.
A fully integrated data platform built exclusively on open standards — every layer governed by a vendor-neutral body, swappable at will.
| Capability | Technology | Lock-in risk |
|---|---|---|
| Data format | Apache Iceberg | none — open table format |
| Data catalog | Apache Polaris | none — open REST catalog |
| Query engine | SQE (Flight SQL) · Trino · Spark Connect | none — ANSI SQL, JDBC/ODBC |
| Identity | Keycloak / OpenID Connect | none — any OIDC provider |
| Authorization | OPA + Rego policies | none — open policy standard |
| Storage | Any S3-compatible backend | none — standard S3 API |
Browse catalogs, namespaces, and tables with schema inspection and Databricks-style column profiling.
Execute SQL via SQE (Arrow Flight SQL), Trino, or Spark Connect with inline results, history, and row counts.
Browser-based IDE: file editor, git operations, build/test/run, and dbt model lineage visualization.
Context-aware assistant powered by a local LLM with MCP tool integration. Schema-aware natural-language SQL.
Visual ODCS v3.1.0 editor with quality checks, import from catalog, and dbt export.
Table-level access control via OPA Rego policies, identity from Keycloak. service_admin → table_reader.
OpenTelemetry traces, OCSF audit logging, Jaeger UI — see every query and access decision.
dbt model lineage with auto-layout, column-level tracking, and search across the warehouse.
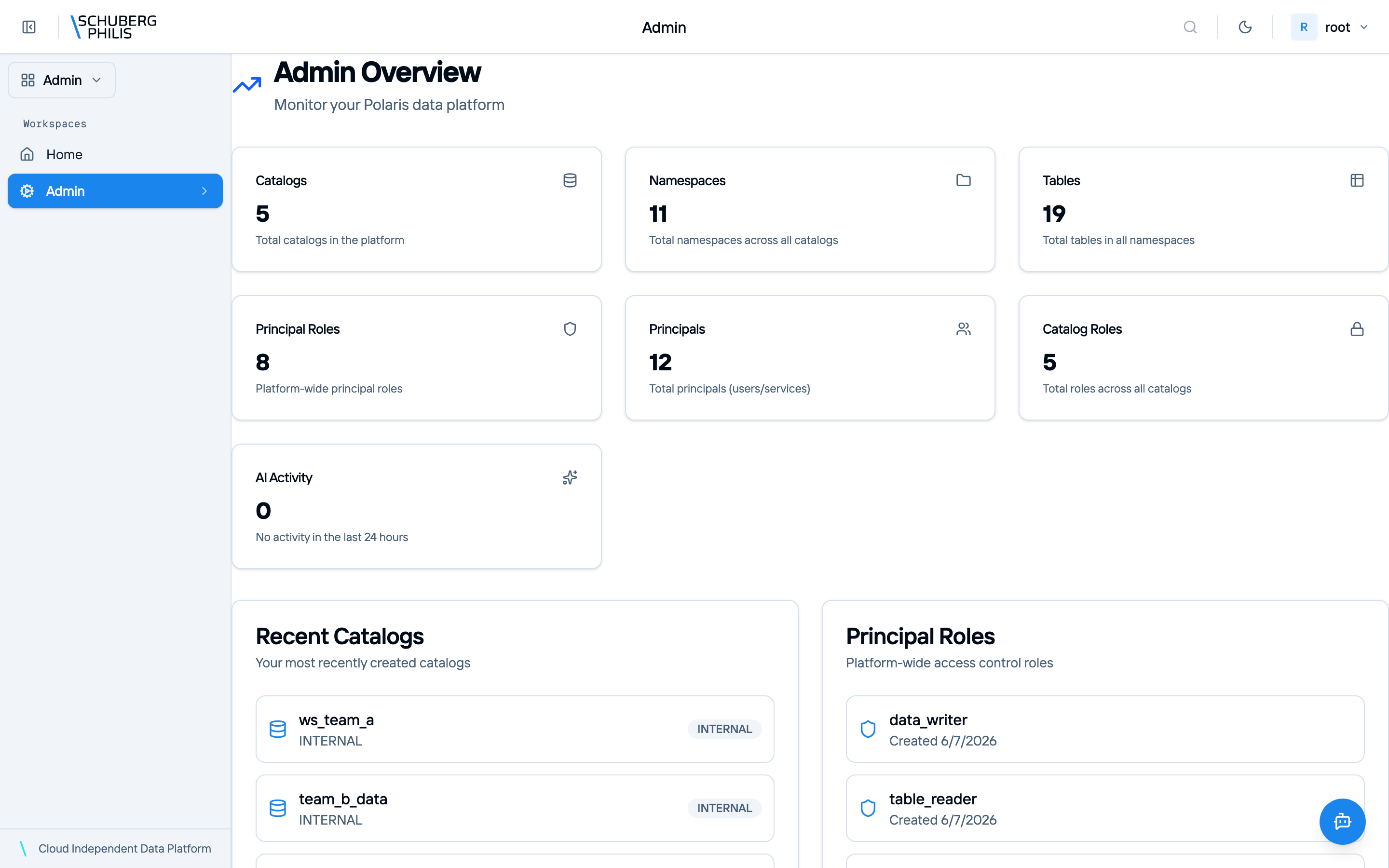
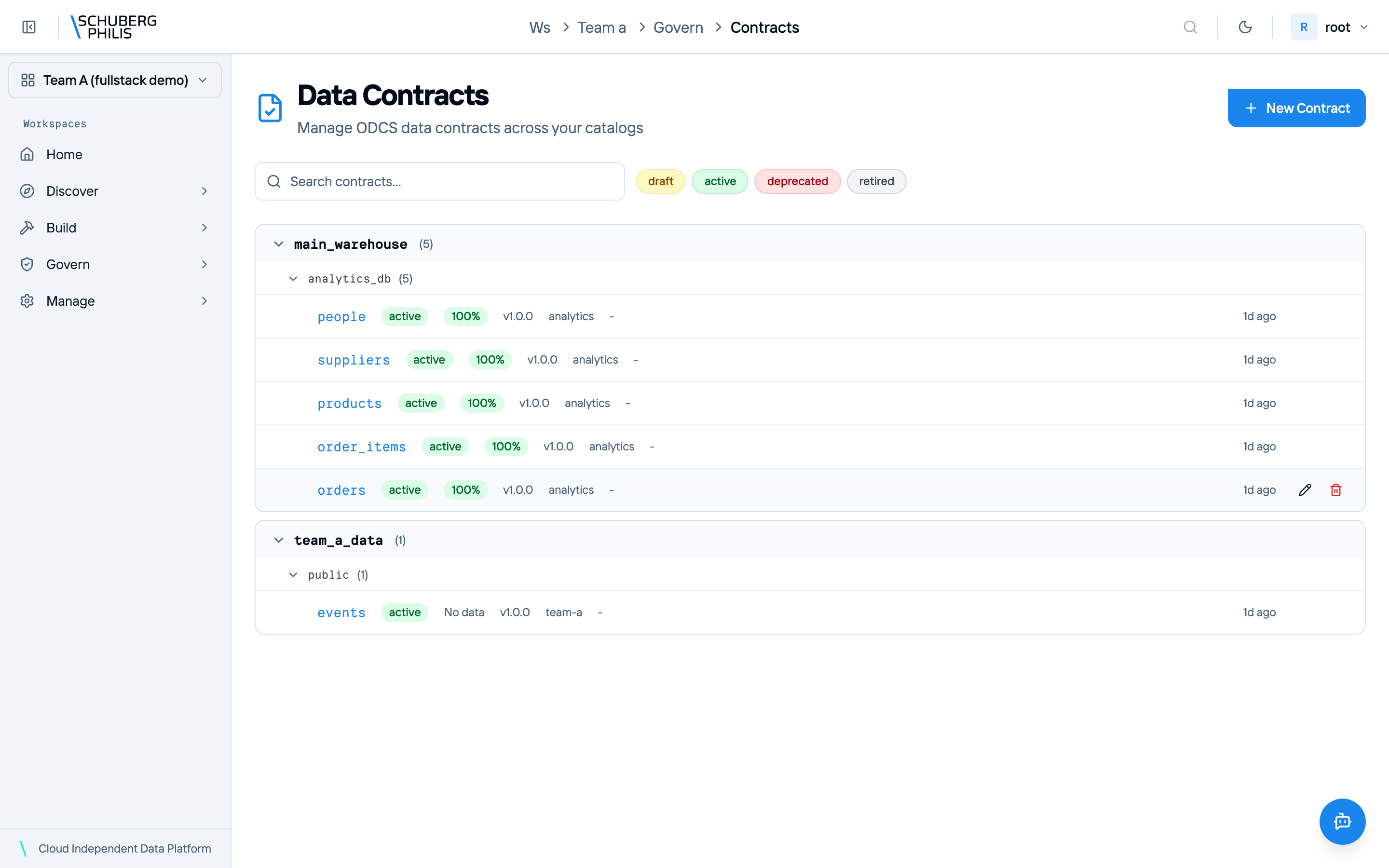
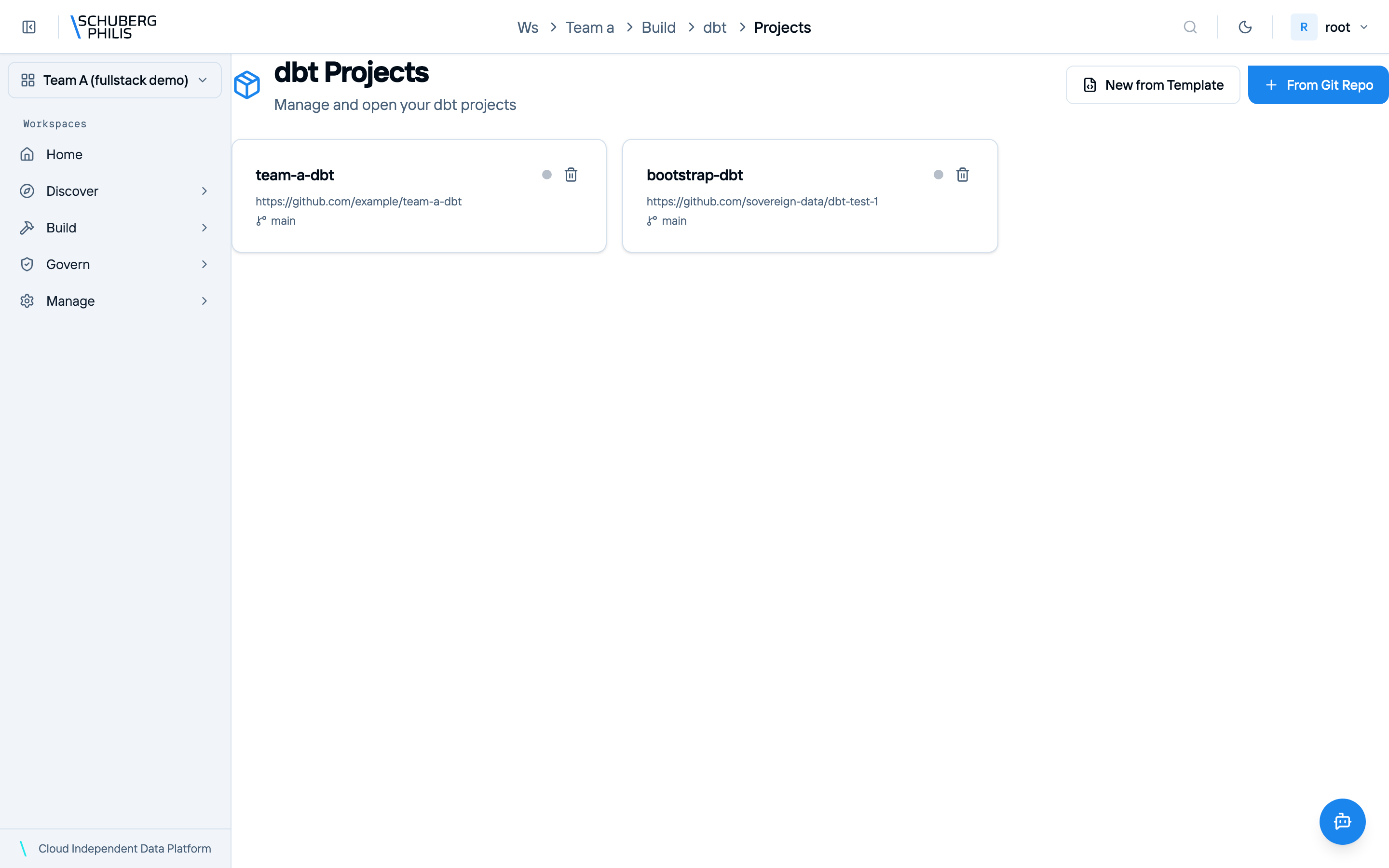
Flagship views — query editor, catalog explorer, and lineage — join the gallery in a later beta drop.
The sqe deployment mode runs the Sovereign Query Engine in place of Trino: Arrow Flight SQL on the wire, per-query identity, and highly Iceberg-compatible reads and writes — V2 and V3. Every query runs as the authenticated user; the bearer token flows through to the catalog and storage.
SQE speaks the Trino HTTP protocol too, so existing clients connect unchanged — or swap in Trino itself. For heavy data engineering, Spark Connect runs against the same Iceberg tables, no copies. Either way it's ANSI SQL over standard JDBC/ODBC — no proprietary drivers.
Tableau · Power BI · DBeaver · DataGrip · dbt · Python/pandas · Spark Connect · the built-in Query Editor — all via Flight SQL or standard JDBC/ODBC. No data copying; queries run against data in place.
OpenID Connect standard — swap for Okta, Azure AD, or any OIDC provider. SSO, MFA, user federation. BFF-style auth: no tokens exposed to the browser. Group and role claims minted into every token.
One policy engine for the whole platform. Catalog-level (catalogs, namespaces, tables), query-level (execution, visibility, row filtering). Policy-as-code: version, review, and audit every access rule. Roles from service_admin to table_reader.
GRANT and REVOKE privileges on catalogs, namespaces, and tables using Polaris's native RBAC security model — then layer OPA policies on top for row- and column-level rules. Standard, portable grants; no vendor-specific access model to migrate away from.
The same open stack everywhere — no managed-service lock-in, no per-query fees.
Production deploys via Helm charts on any conformant Kubernetes: Polaris, the query engine (SQE or Trino), Spark Connect, Keycloak, OPA, and the portals — with horizontal scaling and Argo CD GitOps delivery. Storage is any S3-compatible backend.
Beta: public Helm charts and a hosted demo are on the way.
| This platform | Typical cloud DW | |
|---|---|---|
| Vendor lock-in | zero — open source | deep — proprietary |
| Data format | Apache Iceberg | proprietary internal |
| Data location | any cloud / on-prem | vendor cloud only |
| Identity provider | any OIDC | vendor IAM only |
| Authorization | OPA — policy-as-code | built-in, non-portable |
| Query engine | SQE / Trino — standard SQL | proprietary drivers |
| AI analytics | local or cloud LLM — your choice | vendor's AI service |
| Exit strategy | walk away — data is Iceberg/Parquet | multi-year migration |
| Cost model | infrastructure only | per-query + markup |